

Over the past ten years, Graphic Processing Units (GPUs) have dominated the hardware solution space for artificial intelligence. Currently, these GPU’s are a steady staple in just about every Datacenter offering. NVIDIA and AMD, two of the largest GPU manufacturers, have ridden this wave well and increased their profits and stock prices dramatically.
However, there appears to be a new challenger on the horizon – the Field Programmable Gate Array (FPGA), which according to some, may be an even better hardware platform for AI than the GPU.
“Artificial intelligence (AI) is evolving rapidly, with new neural network models, techniques, and use cases emerging regularly. While there is no single architecture that works best for all machine and deep learning applications, FPGAs can offer distinct advantages over GPUs and other types of hardware in certain use cases” Intel [1].
“Achronix’s high-performance FPGAs, combined with GDDR6 memory, are the industry’s highest-bandwidth memory solution for accelerating machine learning workloads in data center and automotive applications. This new joint solution addresses many of the inherent challenges in deep neural networks, including storing large data sets, weight parameters and activations in memory. The underlying hardware needs to store, process and rapidly move data between the processor and memory. In addition, it needs to be programmable to allow more efficient implementations for constantly changing machine learning algorithms. Achronix’s next-generation FPGAs have been optimized to process machine learning workloads and currently are the only FPGAs that offer support for GDDR6 memory” Micron Technology [2].
“Today silicon devices (ex: FPGA / SOC / ASIC) with latest process technology node, able to accommodate massive computing elements, memories, math function with increased memory and interface bandwidth, with smaller-footprint and low power. So having a different AI accelerator topology will certainly have advantage like Responsive, Better security, Flexibility, Performance/Watts and Adoptable. This helps in deploying different network models addressing various application and use case scenarios, by having scalable artificial intelligence accelerator for network inference which eventually enable fast prototyping and customization during the deployment” HCL Technologies [3].
In addition, large acquisitions taking place recently speak to this emerging trend from GPU to FPGA.
- 10/27/2020 AMD to Acquire Xilinx, Creating the Industry’s High Performance Computing Leader ($35B deal). Xilinx provides FPGA Leadership across Multiple Process Nodes.
- 9/13/2020 NVIDIA to Acquire Arm for $40 Billion, Creating World’s Premier Computing Company for the Age of AI. Arm provides FPGA solutions via Easy Access to Cortex-M Processors on FPGA.
- 9/9/2019 HCL Technologies to Acquire Sankalp Semiconductor to Enhance Leadership in The Semiconductors and Industrial IOT Spaces. Sankalp Semiconductor provides ASIC/FPGA Design Services.
- 4/16/2019 Intel Acquires UK’s Omnitek to double down on FPGA solutions for video and AI applications.
As shown above, when the two largest GPU manufacturers (NVIDIA and AMD) make large acquisitions of large, established FPGA companies, change is in the wind.
Why Use an FPGA vs. GPU?
FPGA’s “work similarly to GPUs and their threads in CUDA” Ashwin Sing [4]. According to Sing, several benefits of using an FPGA over a GPU include: Lower power consumption, accepted in safety-critical operations, and support for custom data types all of which are ideal for embedded applications used in edge devices such as automatic driving cars.
In addition, the FPGA appears to have one very large and growing advantage over GPU solutions – Memory. As of this writing NVIDIA recently released its 3090 GPU with a whopping 24GB of memory which is a great step for AI model designers given its low sub $1500 price point. However, the amount of memory available to the GPU (or FPGA) directly translates into faster training times for large models which then push the demand for more memory on the edge devices doing the inferencing. With larger amounts of memory, the training process can use larger input image sizes along with larger batches of images during training thus increasing the overall trained image/second throughput. Larger images lead to higher image resolution which then leads to higher training accuracies.
Memory chip specialists like Micron Technologies argue “that hardware accelerators linked to higher memory densities are the best way to accelerate ‘memory bound’ AI applications” [5]. By combining a Xilinx Virtex Ultrascale+ FPGA with up to a massive 512GB of DDR4 memory, Micron is clearly demonstrating a large advantage FPGA’s appear to have over GPU’s.
FPGA AI Challenges
Currently, programming the FPGA for machine learning is complex and difficult for “the requirement for laying out and creating hardware is a large barrier to the use of FPGAs in deep learning” [4]. However specialized compilers such as the one provided by Halide, may be changing this. In 2016, Li et al. proposed “an end-to-end FPGA-based CNN accelerator with all the layers mapped on one chip so that different layers can work concurrently in a pipelined structure to increase the throughput” [6]. An idea further extended by Yang et al. in 2018, “Interstellar: Using Halide’s Scheduling Language to Analyze DNN Accelerators” [7]. According to Yang et al., their FPGA and ASIC back ends to Halide were able to “achieve similar GOPs and DSP utilization when compared against manually optimized designs.”
Compilers do help reduce the complexity, but do not eliminate it which is especially important when using an FPGA device for training an AI solution. During the training process an AI developer is often faced with the problem of diagnosing and debugging their AI model so that it trains properly on their given dataset. Solving the ‘model blow-up’ problem can be difficult without being able to actually visually analyze the data flowing from one layer to the next. In addition, network bottlenecks can be hard to locate when using a large 100+ layer network.
The visual editing and debugging capabilities of the SignalPop AI Designer coupled with the plug-n-play low level software of the MyCaffe AI Platform [8] can help dramatically reduce or eliminate these complexities.
MyCaffe AI Platform Plug-n-Play Architecture
The MyCaffe AI Platform uses a plug-n-play architecture that allows for easy separation of the AI platform (e.g. Solver, Network and Layers) from the low-level primitives that are specific to a given hardware platform (e.g. GPU or FPGA device).

We currently use this architecture to support the various and rapidly changing versions of CUDA and cuDNN produced by NVIDIA. However, this architecture lends itself well to the future movement from the GPU to FPGA devices discussed above. And changing between hardware support is quick and easy. From within the SignalPop AI Designer, the user just selects the hardware DLL from a menu item. And when programming MyCaffe, the path to the desired hardware DLL is passed to the MyCaffeControl during initialization.

With technologies like Halide to generate much of the low-level software that runs on the FPGA, the MyCaffe plug-n-play architecture is well suited to support a new low-level DLL designed specifically for FPGA devices.
Not only does adding FPGA support expand the reach of the MyCaffe AI Platform to the potential future of AI, it does so for over 6.2 million C# developers world-wide [9].
The SignalPop AI Designer
Combining the plug-n-play design of MyCaffe with the visual editing and debugging features of The SignalPop AI Designer can dramatically reduce the complexity of building AI solutions in general and specifically can make it easier develop such solutions for FPGA devices.
Visual Editing
Typically AI models are developed either using a text-based script that describes the model, or by programmically constructing the model by linking one layer to another. The SignalPop AI Designer transforms the prototxt model descriptions (used by the original CAFFE [10] open-source platform) into a visual representation of the model that allows for easy parameter changing, one-click help, and live debugging.

Developers can easily switch between the visual editor and text script editor and when the model is saved, the final model descriptor prototxt is produced.
Easy Transfer Learning
After constructing the AI model, developers can easily import weights from other pre-trained models for quick transfer learning.

Weights can be imported from models in the ONNX or native CAFFE file formats.
Visual Model Debugging
The SignalPop AI Designer allows visualization of the trained weights, locating bottlenecks, inspecting individual layers and visualizing the data that flows between layers are all key aspects to debugging complex AI models.
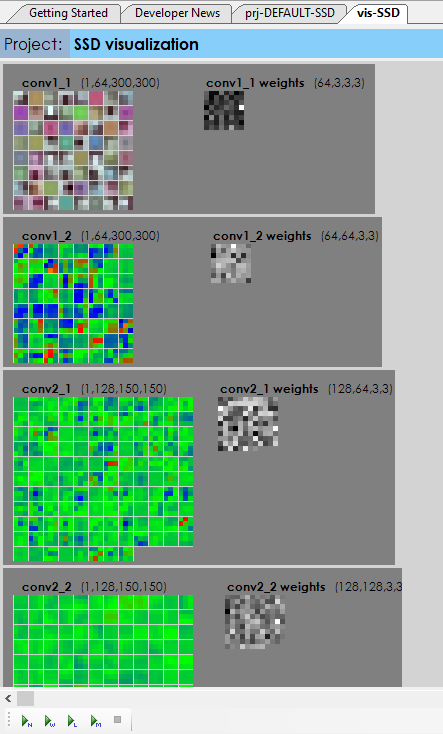
By allowing easy weight visualizations, the developer can quickly see if the expected weights are loaded during training.

During training, developers can optionally view the data as it flows through the network in the Debug window and observe the timing of each layers forward and backward pass thus easily showing the designer where the network’s bottlenecks are.

Right clicking on a debug layer while training allows for easy embedding visualization using the TSNE algorithm.

Right clicking on a model layer link while training allows the designer to see the actual data flowing between the layers on both the forward and backward passes.
Summary
The MyCaffe AI Platform gives the AI developer flexibility to target different hardware platforms while the SignalPop AI Designer provides an easy to use visual development environment.
Combining these two offers an AI platform uniquely suited for creating customized solutions and is perfectly positioned for future generations of FPGA AI challenges that may soon supersede the GPU solutions of today.
If you are an FPGA manufacturer searching for an AI software solution that makes AI programming easier, contact us for we would like to work with you!
[1] Intel, FPGA vs. GPU for Deep Learning, 2020.
[2] Micron Technology, Micron and Achronix Deliver Next-Generation FPGAs Powered by High Performance GDDR6 Memory for Machine Learning Applications, 2018.
[3] HCL Technologies, Edge Computing using AI Accelerators, 2020.
[4] Ashwin Singh, Hardware for Deep Learning: Known Your Options, Towards Data Science, 2020.
[5] George Leopold, Micron Deep Learning Accelerator Gets Memory Boost, Interprise AI, 2020.
[6] Huimin Li, Xitan Fan, Wei Cao, Xeugong Wei and Lingli Wang A high performance FPGA-based accelerator for large-scale convolutional neural networks, IEEE, 2016.
[7]Xuan Yang, Mingyu Gao, Qiaoyi Liu, Jeff Ou Setter, Jing Pu, Ankita Nayak, Steven E. Bell, Kaidi Cao, Heonjae Ha, Priyanka Raina, Christos Kozyrakis and Mark Horowitz, Interstellar: Using Halide’s Scheduling Language to Analyze DNN Accelerators, arXiv 1809.04070, 2018, 2020.
[8] Dave Brown MyCaffe: A Complete C# Re-Write of Caffe with Reinforcement Learning, arXiv:1810.02272, 2018.
[9] DAXX How Many Software Developers Are in the US and the World, 2020.
[10] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama and Trevor Darrell Caffe: Convolutional Architecture for Fast Feature Embedding, arXiv:1408.5093v1, 2014.